今天要討論的問題,可以用下面這張圖看出來: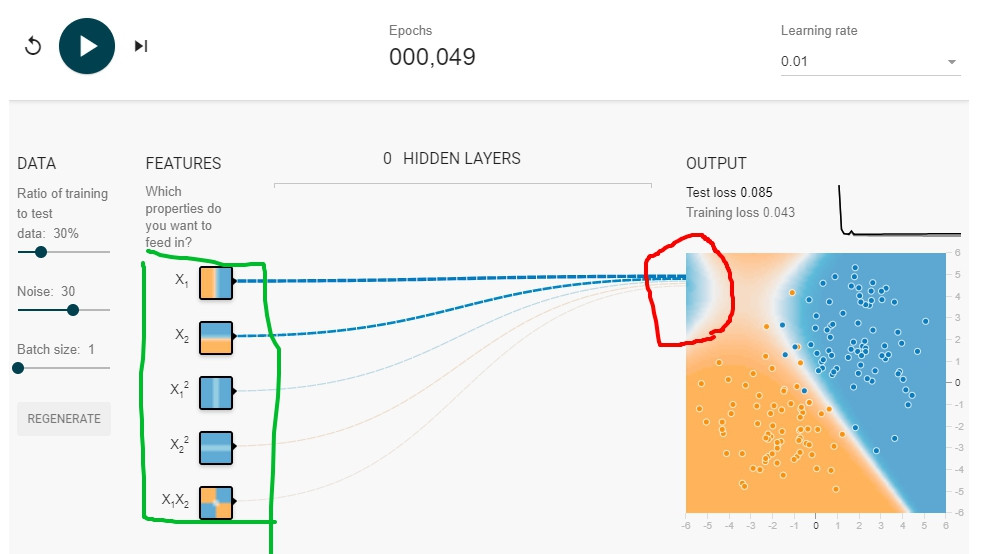
看到了嗎?紅色圈圈處多了一塊導致model overfit的部分。問題的來源就是綠色的features會不會給太多?Task 2說這個model其實不需要這麼複雜,不用預測得太美,只要x1, x2 features(綠色最上面兩個)就好。
看看Google提供的圖:
為什麼Validation data的loss後面會高起來?跟Overfit有什麼關係?一開始很難理解,我再貼一張自己畫的圖,來看看紅色星星的new data: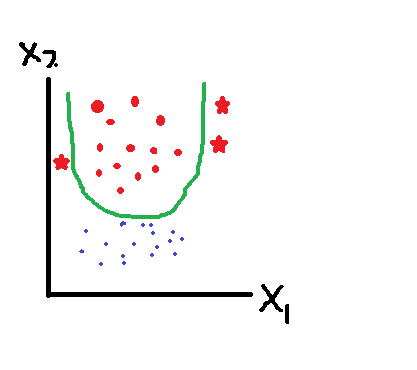
Seeee, 預測錯了,如果是原先model像下面一樣是線性,就沒問題了: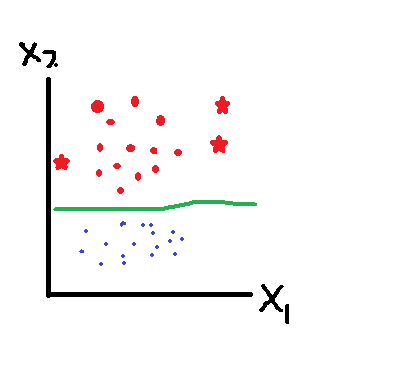
怎麼辦到的?原先的我們只是要最小化loss,因為這個目標,才讓model overfitting。
data在某個model裡時最小的loss可以表示成min(Loss(data|model))。現在饒口一點,我要data在model裡時,loss 與 複雜度 的和最小,可以表示成min(Loss(data|model) + complexity(model))。
複雜度又有兩種定義:
好,這邊要介紹L_2 regularization: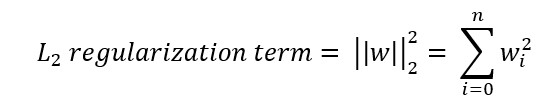
為什麼要加起來?想像一下[w1, w2, w3] = [0.1, 3, 0.2], 此時w1^2 + w2^2 + w3^2 = 9.05,幾乎等於w2^2,就是要特別調整過大的weight,讓整個model不會被影響太多。
把L_2 regularization 乘上 lambda後去評估model,會變成下面這樣:
它除了可以讓weight values更接近0,也可以讓weights的平均值更接近0,而且呈現normal distribution。下面左圖是高lambda,右圖是低lambda所造成的weights distribution‧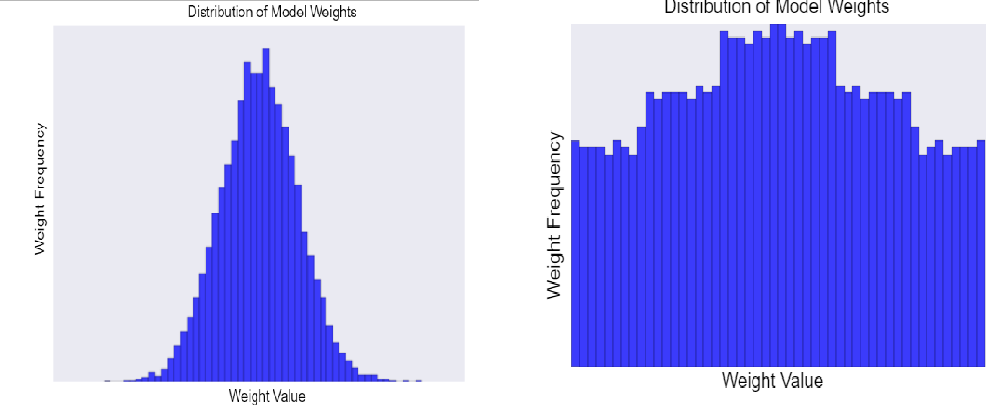
問題是Lambda的值要怎麼取,也是一門學問。Lambda越高,model越簡單,你的model就學的不夠好(A猜成B、B猜成A);但Lambda越低,model越複雜,你的model就學的太好以至於new data很難識別(A猜成A、B也猜成A)。
If your lambda value is too high, your model will be simple, but you run the risk of underfitting your data. Your model won't learn enough about the training data to make useful predictions.
If your lambda value is too low, your model will be more complex, and you run the risk of overfitting your data. Your model will learn too much about the particularities of the training data, and won't be able to generalize to new data.
所以Lambda應該要跟data息息相關,要慢慢tune才對。
最後玩一玩L_2 regularization吧。 Playground


 iThome鐵人賽
iThome鐵人賽